Defining and Enhancing Quality-of-Experience in LLM-Based Text Streaming Services
Jiachen Liu, Zhiyu Wu, Jae-Won Chung University of Michigan, Fan Lai UIUC, Myungjin Lee Cisco Systems, Mosharaf Chowdhury University of Michigan.
TL;DR: Large language models (LLMs) have revolutionized text-based interactions, enabling services from real-time translation to AI-driven chatbots. By streaming tokens to users, akin to video streaming, such text streaming service allows users to digest the content incrementally, whether in text or speech form. However, existing serving systems primarily focus on optimizing server-side aggregated metrics while ignoring individual user experience, leading to unfavorable service quality or poor Quality-of-Experience (QoE) under high and/or bursty load.
In this project, we first formally define QoE in text streaming services by considering the end-to-end token delivery process. Thereafter, we propose Andes, a QoE-aware serving system that enhances user experience. Andes achieves this by strategically scheduling multiple requests on contended GPU resources, prioritizing them based on their resource demands and service acquired. Our evaluations demonstrate that, compared to the state-of-the-art LLM serving systems like vLLM, Andes improves the average QoE by up to 3.2× under high request rate, or alternatively, it attains up to 1.6× higher request rate while preserving high QoE.
A User-Side Story
Imagine three different scenarios where text is streamed to users. Despite all having the same efficiency in token generation throughput, their user experiences vary dramatically:

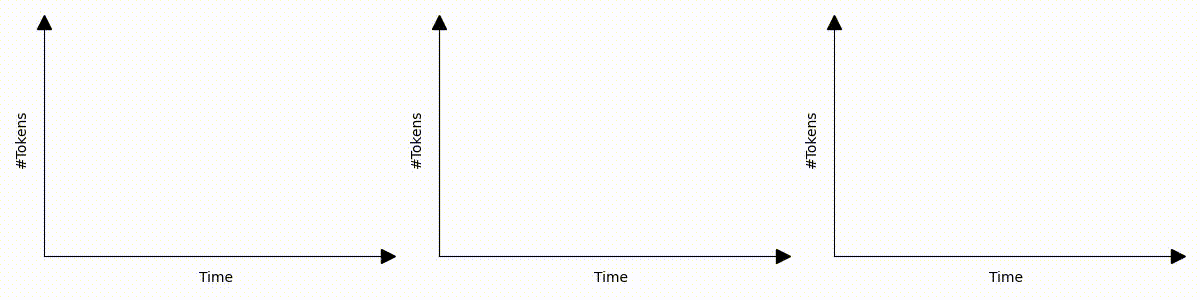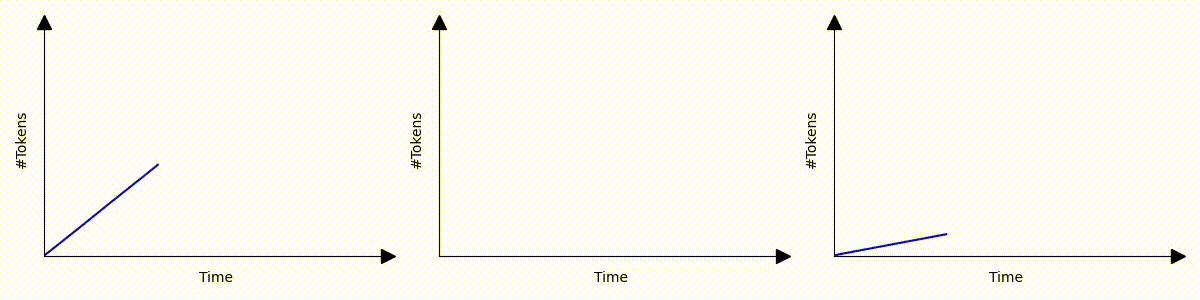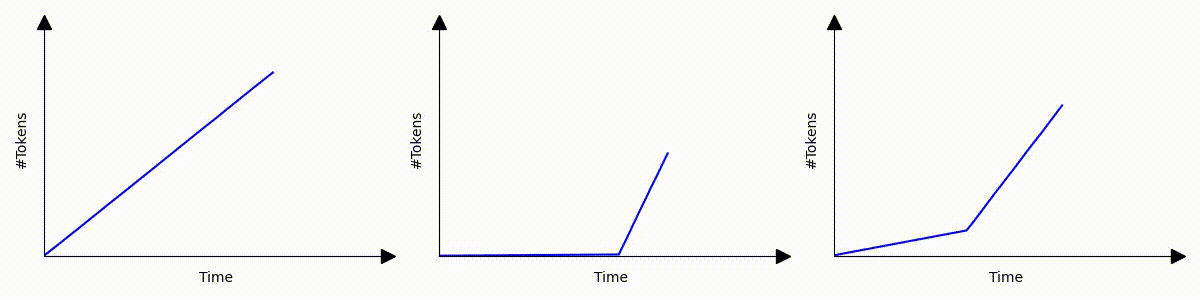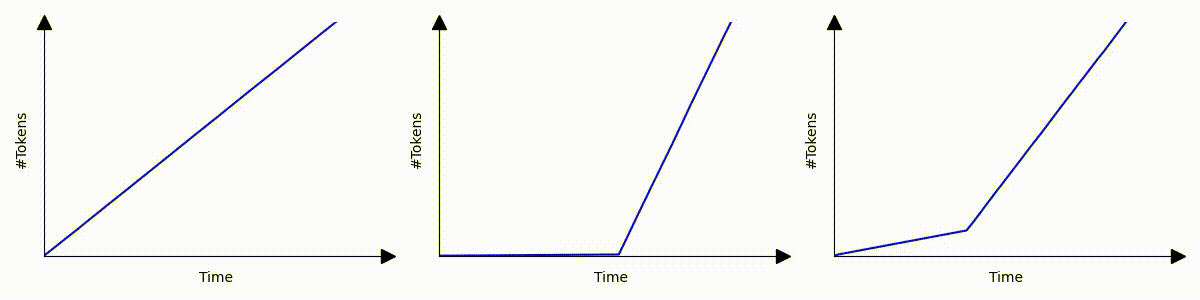
Despite generating the same response within the same time frame; even scenarios 1 and 3, which have identical average or P90 time per output token latency, these scenarios deliver vastly different user experiences. The slowdown that happens in scenario 2 and 3 are common under high server loads, such as during bursty request periods or when managing requests with extensive context.
It is crucial that the initial response is prompt and that subsequent tokens are delivered at a pace aligned with the user’s ability to digest them. However, the expected token delivery speed (TDS) differs from request to request. For instance, a chat service utilizing text-to-speech to deliver responses may have different pacing requirements than a text-based chat service, because a user’s speaking speed is often slower than their reading speed, but it may require smaller time to first token (TTFT) to better resemble real-life verbal conversations.
In sum, QoE in text streaming shouldn’t be just another aggregated number to track; it needs to capture the entire user interaction from start to finish. Please refer to Section 3.1 of our paper for more detailed QoE formulation.
System Imbalance and Opportunity
Current first-come, first-served (FCFS) scheduling policy, commonly adopted in LLM serving systems, fails to account for the QoE requirements of individual requests and cannot efficiently utilize resources, especially when the request load surpasses the server’s capacity. As shown in Figure 2, they often lead to misaligned user experiences, where the timing of token delivery doesn’t necessarily meet user needs.
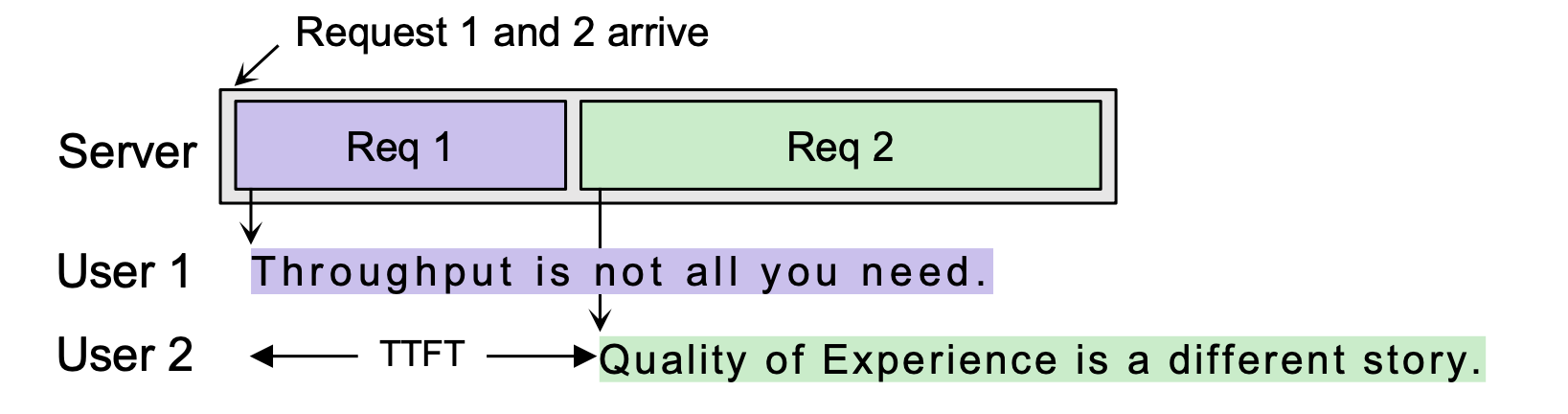
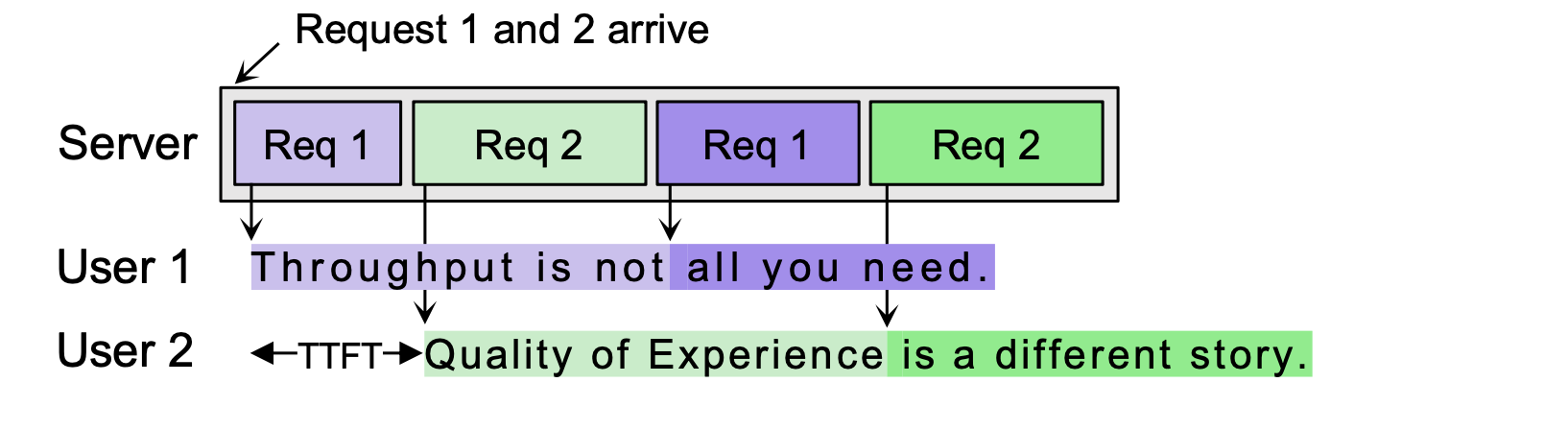
We notice that especially under high request load, uneven user experiences arise as shown in Figure 3: (1) certain users may encounter extended time to first token, or TTFT; (2) conversely, other users might receive tokens at a pace (TDS) surpassing their digestion ability.
Usually, in order to preserve good user experience, the service provider must provision more compute resources proportional to the excess request load, leading to higher costs.
However, we observe that there is an opportunity to optimize user experience by balancing prolonged TTFT and excessively fast token generation speed. By temporarily pausing the response generation for requests with already sufficient tokens generated, we can spare the limited GPU resources to other pending requests. This approach leverages the disparity between the expected and actual token generation speeds, optimizing both resource efficiency and user satisfaction.
Introducing Andes: Towards a Better User Experience in Text Streaming Services
We propose Andes, an LLM serving system that optimizes the overall QoE of text streaming services. Andes employs a dynamic priority-based preemptive scheduler that operates at the granularity of tokens. Andes strategically allocates resources to more urgent requests and preempts requests that have already received sufficient service, all to enhance QoE. Additionally, Andes takes the resource demand of each request into account while prioritizing resources. Together, we formulate the request scheduling problem as a knapsack variant and propose a heuristic to solve it.
By satisfying more requests with high QoE using the same amount of resource, Andes eliminates the need for additional resource provisioning, thus reducing LLM serving cost. Andes also co-designs a client-side token buffer that temporarily withholds excess tokens and displays them to the user at their expected pace. This design ensures users experience smooth token delivery, oblivious to the intricacies of server-side scheduling or network fluctuations.
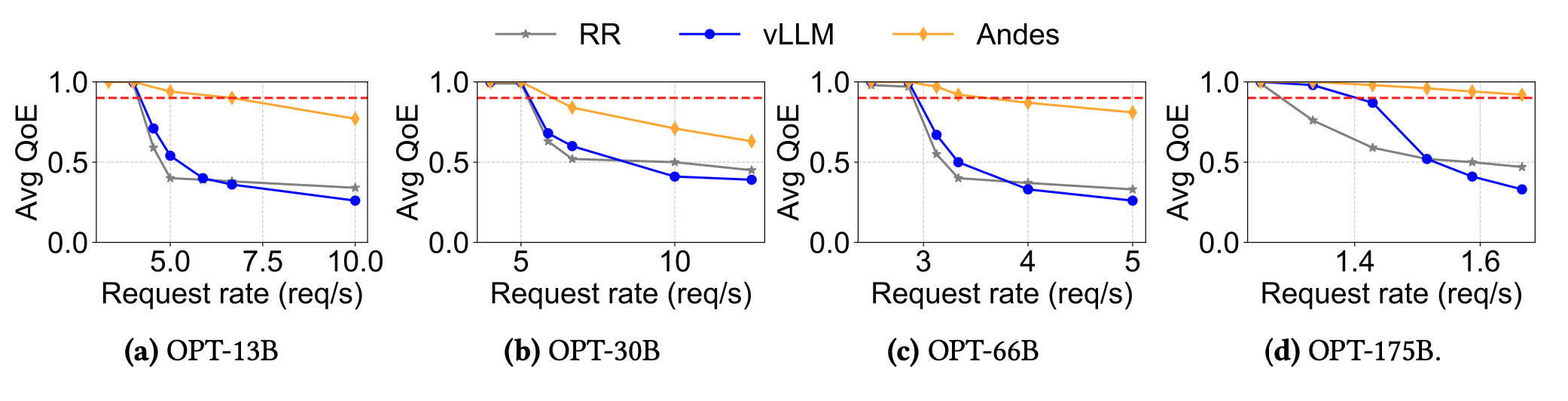
In our evaluation of Andes, we show
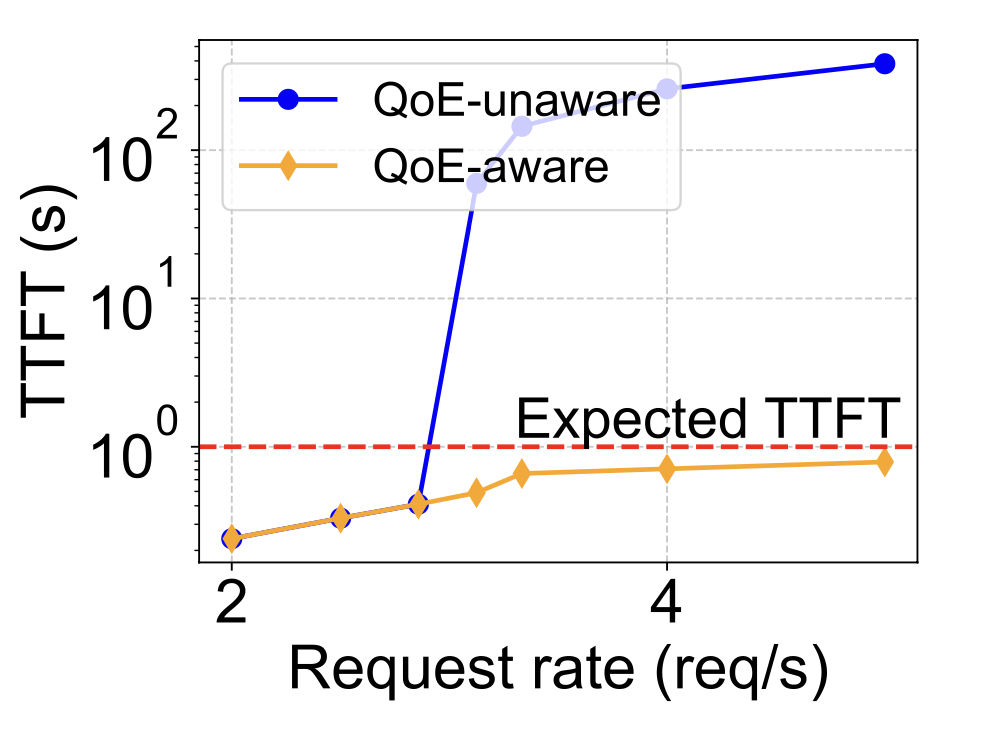
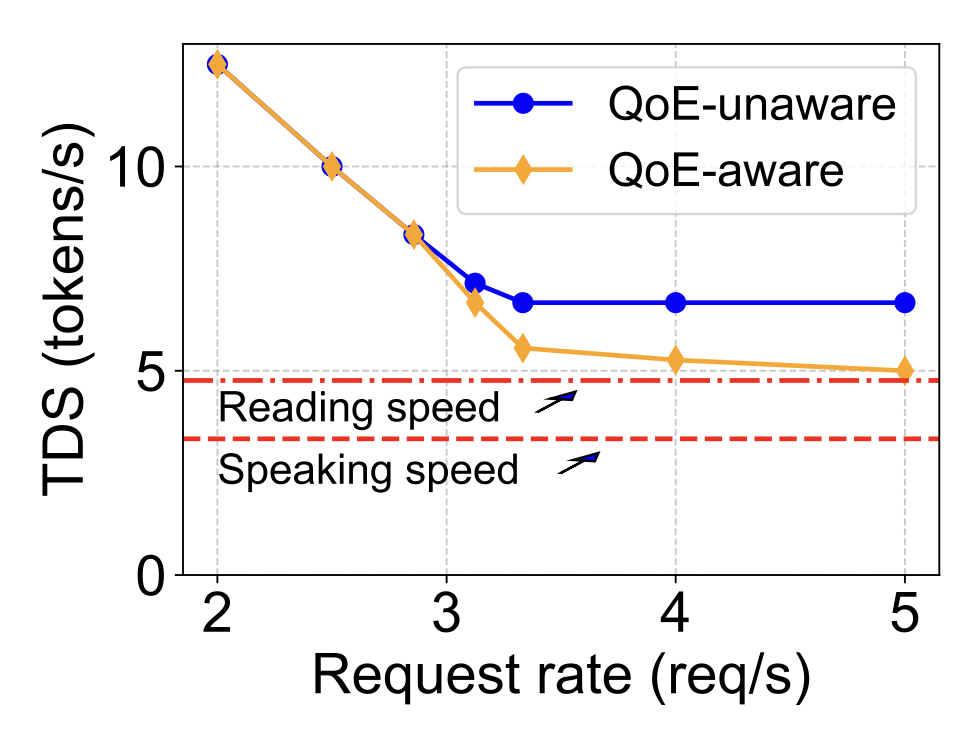
- Andes improves the average QoE up to 3.2× when the system experiences high/bursty load. Specifically, Andes significantly improves TTFT, while maintaining TDS above user expected speed.
- Andes can manage up to 1.6× higher request rates while preserving high QoE without additional resources, significantly reducing the serving cost.